Cold Start Initialization
SFT-based: fine-tune student on teacher trajectories for stable starting point. Model Merging: superpose anisotropic teacher priors without training cost, consistently outperforming SFT across all OOD benchmarks.
To our best knowledge, we present the first integration of On-Policy Distillation into Flow Matching models, achieving exceptional multi-task performance across diverse generative domains.
1University of Science and Technology of China (USTC) · 2UCLA · 3CUHK · 4Xiaohongshu
*Equal Contribution · †Project Leader · ‡Corresponding Author
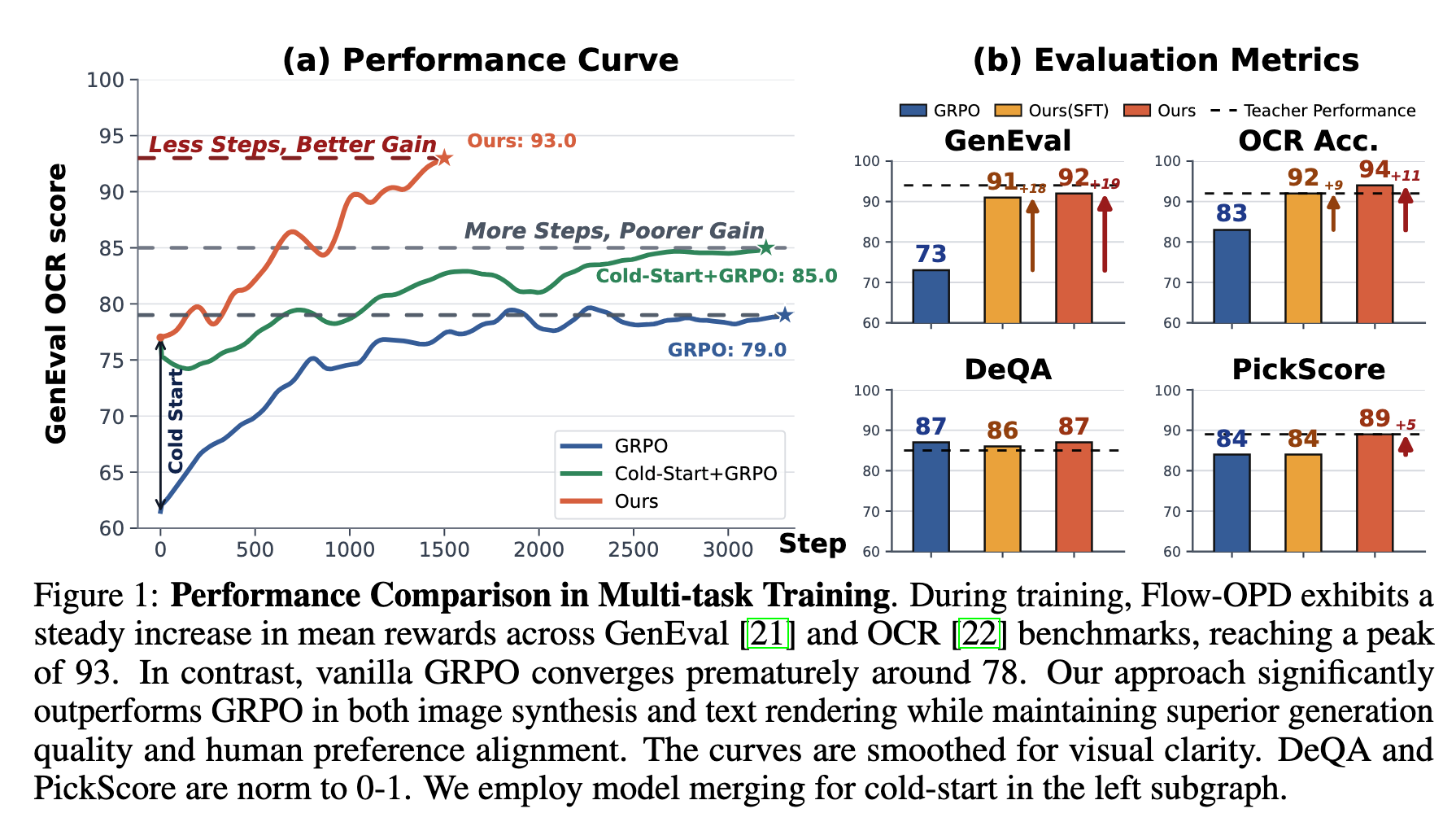
We identify two critical bottlenecks in multi-task Flow Matching training: reward sparsity and gradient interference. Standard GRPO works in single-task settings but catastrophically degrades in multi-task settings due to divergent gradients compressing high-dimensional image space into a single scalar reward. Flow-OPD integrates On-Policy Distillation into the Flow Matching pipeline, replacing sparse scalar rewards with dense, trajectory-level, multi-teacher vector field supervision. Evaluated on SD-3.5-Medium, Flow-OPD achieves +18pt average improvement over vanilla GRPO and surpasses individual teacher models on OCR and DeQA.
Flow-OPD decouples expertise acquisition from model unification through a two-stage process: Cold Start initialization followed by Multi-Teacher On-Policy Distillation.
SFT-based: fine-tune student on teacher trajectories for stable starting point. Model Merging: superpose anisotropic teacher priors without training cost, consistently outperforming SFT across all OOD benchmarks.
Convert the deterministic ODE into a Stochastic Differential Equation (SDE) for stochastic exploration. Sample G trajectories per prompt to generate on-policy marginal distributions.
Each teacher acts as a Generative Reward Model (GRM), returning a full vector field
vϕk. Dynamic routing αk selects
domain experts from GenEval, OCR, DeQA and PickScore.
A task-agnostic aesthetic teacher prevents background mode collapse and semantic redundancy. KL regularization from the aesthetic teacher acts as a continuous elastic anchor, decoupling functional alignment from stylistic preservation.
Converting the deterministic ODE into an SDE for stochastic on-policy exploration. Sampling G trajectories per prompt generates marginal distribution xt ∼ ρtθ(⊵ | c).
Each task ᴴk has a dedicated domain expert teacher ϕk. Data belonging to task k is routed exclusively to its corresponding teacher, providing dense supervision without gradient interference across domains.
Reverse KL divergence in the SDE framework reduces to a time-weighted L2 distance between student and teacher vector fields.
Clipped surrogate objective bounds the policy trust region. Gradients flow exclusively through the policy ratio ρ, preserving fine-grained credit assignment.
MAR introduces KL regularization from a frozen aesthetic teacher as a continuous elastic anchor, preventing aesthetic degradation while absorbing functional intelligence.
Evaluated on SD-3.5-Medium across GenEval, OCR, DeQA, and PickScore. Training on 4×8 H800 GPUs (~50 hours).
| Model | GenEval ↑ | OCR Acc. ↑ | DeQA ↑ | PickScore ↑ | Average ↑ |
|---|---|---|---|---|---|
| SD-3.5-M (base) | 0.63 | 0.59 | 4.07 | 21.64 | 0.72 |
| + GRPO-GenEval | 0.94 | 0.65 | 4.01 | 21.53 | 0.81 |
| + GRPO-OCR | 0.64 | 0.92 | 4.06 | 21.69 | 0.80 |
| + GRPO-DeQA | 0.64 | 0.66 | 4.23 | 23.02 | 0.76 |
| + GRPO-PickScore | 0.51 | 0.69 | 4.22 | 23.19 | 0.73 |
| GRPO-Mix (3:1:1) | 0.73 | 0.83 | 4.33 | 21.84 | 0.82 |
| Ours — SFT Init | 0.91 | 0.92 | 4.29 | 21.83 | 0.88 |
| Ours — Merge Init | 0.92 | 0.94 | 4.35 | 23.08 | 0.90 |
T2I-CompBench (OOD Generalization). Model Merging optimally leverages homogeneous teacher priors without additional training cost.
| Model | Color | Shape | 3D-Spatial | Numeracy | Overall |
|---|---|---|---|---|---|
| GRPO-Mix | 0.692 | 0.611 | 0.422 | 0.641 | 0.587 |
| Cold Start (w/o OPD) | 0.710 | 0.613 | 0.425 | 0.646 | 0.595 |
| Flow-OPD (Merge Init) | 0.719 | 0.629 | 0.457 | 0.684 | 0.618 |
MAR prevents reward hacking by anchoring optimization to a task-agnostic aesthetic manifold.
| Model | ImageReward ↑ | Aesthetic ↑ | HPS-v2.1 ↑ | QwenVL ↑ |
|---|---|---|---|---|
| SD-3.5-M (base) | 1.02 | 5.87 | 0.298 | 3.45 |
| GRPO-Mix | 1.23 | 5.93 | 0.310 | 3.88 |
| Flow-OPD w/o MAR | 1.26 | 5.89 | 0.300 | 3.82 |
| Flow-OPD (w/ MAR) | 1.36 | 6.23 | 0.330 | 4.05 |



